‘Google for DNA’ permite pesquisas rápidas de texto completo em vastos arquivos genéticos
. DOI: 10.1038/s41586-025-09603-w")
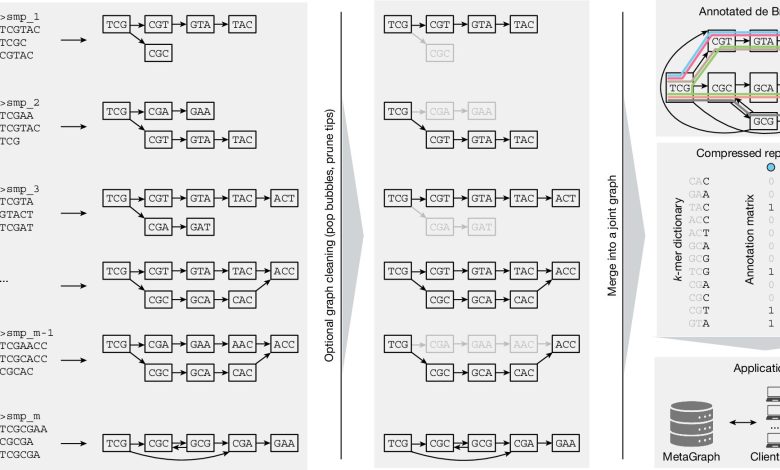
A estrutura MetaGraph. Crédito: Natureza (2025). DOI: 10.1038/s41586-025-09603-w
Doenças hereditárias raras podem ser identificadas em pacientes e podem ser detectadas mutações específicas em células tumorais – o sequenciamento de DNA revolucionou a pesquisa biomédica há décadas. Nos últimos anos, novos métodos de sequenciação (sequenciação de próxima geração), em particular, resultaram em numerosos avanços científicos. Em 2020/2021, por exemplo, permitiram a rápida descodificação e monitorização global do genoma do SARS-CoV-2.
Enquanto isso, cada vez mais pesquisadores estão disponibilizando publicamente os resultados do DNA sequenciado. Isto deu origem à criação de enormes volumes de dados, que são armazenados em bases de dados centrais como o SRA americano (Sequence Read Archive) ou o ENA europeu (European Nucleotide Archive). Cerca de 100 petabytes de dados são armazenados lá – aproximadamente a mesma quantidade de todo o texto na Internet, sendo um petabyte equivalente a um milhão de gigabytes.


Até à data, os cientistas biomédicos necessitaram de um enorme poder computacional e de outros recursos para pesquisar esta quantidade de sequências de ADN e compará-las com as suas próprias sequências – tornando a pesquisa eficiente nessas montanhas de dados uma pura impossibilidade. Os cientistas da computação da ETH Zurich resolveram agora este problema.
Pesquisa de texto completo em vez de baixar conjuntos de dados inteiros
Os cientistas desenvolveram um método que encurta e facilita muito essa busca. A pesquisa está publicada na revista Natureza.
A ferramenta digital “MetaGraph” pesquisa os dados brutos de todas as sequências de DNA ou RNA armazenadas nos bancos de dados – exatamente como um mecanismo de busca convencional na Internet. Depois de inserir uma sequência de seu interesse como texto completo em uma máscara de pesquisa, os pesquisadores podem descobrir em segundos ou minutos, dependendo da consulta, onde ela já apareceu.
“É uma espécie de Google para DNA”, diz o professor Gunnar Rätsch, cientista de dados do Departamento de Ciência da Computação da ETH Zurique. Até agora, os pesquisadores tinham que pesquisar nas bases de dados metadados descritivos. Para acessar os dados brutos, eles tiveram que baixar os respectivos conjuntos de dados. Essas pesquisas eram incompletas, demoradas e caras.
O “MetaGraph” é comparativamente favorável em termos de custos, como afirmam os pesquisadores em seu estudo. A representação de todas as sequências biológicas públicas caberia em alguns discos rígidos de computador, enquanto consultas maiores não deveriam custar mais do que 0,74 dólares por megabase.
Como o motor de busca de ADN que os investigadores da ETH desenvolveram também é preciso e eficiente, pode ajudar a acelerar a investigação genética – por exemplo, no caso de agentes patogénicos pouco investigados ou de novas pandemias.
Desta forma, a ferramenta poderá tornar-se um catalisador na investigação sobre a resistência aos antibióticos: por exemplo, identificando genes de resistência ou vírus úteis que podem destruir bactérias – conhecidas como bacteriófagos – nas bases de dados.
Compressão por um fator de 300
No estudo, os pesquisadores da ETH demonstram como funciona o MetaGraph: a ferramenta indexa os dados e os apresenta de forma compactada. Isto é conseguido por meio de gráficos matemáticos complexos que melhoram a estrutura dos dados – semelhantes a programas de planilhas como o Excel. “Matematicamente falando, é uma matriz enorme com milhões de colunas e trilhões de linhas”, como afirma Rätsch.
A ideia de tornar grandes quantidades de dados pesquisáveis com a ajuda de índices é uma prática padrão na pesquisa em ciência da computação.
O que há de novo no trabalho dos investigadores da ETH, no entanto, é a ligação complexa de dados brutos e metadados e a compressão por um factor de cerca de 300, semelhante a um resumo de livro: já não contém todas as palavras, mas todas as principais histórias e ligações permanecem intactas – mais compactas, mas sem qualquer perda relevante de informação.
“Estamos ultrapassando os limites do possível para manter os conjuntos de dados o mais compactos possível, sem perder as informações necessárias”, diz o Dr. André Kahles, que, como Rätsch, é membro do Grupo de Informática Biomédica da ETH Zurique.
Em contraste com outras máscaras de busca de DNA atualmente em pesquisa, a abordagem dos pesquisadores da ETH é escalável. Isso significa que quanto maior a quantidade de dados consultados, menos poder computacional adicional a ferramenta requer.
Metade dos dados já está disponível agora
Os pesquisadores da ETH apresentaram o MetaGraph pela primeira vez em 2020 e têm melhorado continuamente desde então. A ferramenta já está disponível para consultas (link). Ele fornece um mecanismo de busca de texto completo para milhões de conjuntos de sequências de DNA e RNA, bem como proteínas de vírus, bactérias, fungos, plantas, animais e humanos.
Atualmente, pouco menos da metade dos conjuntos de dados de sequências disponíveis em todo o mundo são indexados. Segundo Gunnar Rätsch, o restante deverá ocorrer até o final do ano. Dado que o MetaGraph está disponível como código aberto, também pode ser de interesse para empresas farmacêuticas que possuem grandes quantidades de dados de pesquisas internas.
Kahles ainda acredita que é possível que o mecanismo de busca de DNA um dia seja usado por particulares. “No início, mesmo o Google não sabia exatamente para que servia um mecanismo de busca. Se o rápido desenvolvimento no sequenciamento de DNA continuar, pode se tornar comum identificar as plantas de sua varanda com mais precisão.”
Mais informações:
Mikhail Karasikov et al, Pesquisa eficiente e precisa em repositórios de sequências em escala de petabase, Natureza (2025). DOI: 10.1038/s41586-025-09603-w
Citação: ‘Google for DNA’ permite pesquisas rápidas de texto completo em vastos arquivos genéticos (2025, 9 de outubro) recuperados em 9 de outubro de 2025 em https://medicalxpress.com/news/2025-10-google-dna-enables-rapid-full.html
Este documento está sujeito a direitos autorais. Além de qualquer negociação justa para fins de estudo ou pesquisa privada, nenhuma parte pode ser reproduzida sem permissão por escrito. O conteúdo é fornecido apenas para fins informativos.